本文将介绍StarRocks迁移至EMR Serverless的整体解决方案及具体迁移步骤。该迁移方案仅供参考,您需要结合实际业务情况进行调整与优化,以更好地满足您的需求。
迁移流程
整体迁移流程如下图所示,涵盖了作业改写、作业双跑、数据校验、业务校验以及割接等多个步骤。

前期评估
确认当前集群情况
请确认当前集群的基本情况,包括集群的版本,FE规格和数量,BE规格和数量,以及负载等信息。
集群信息 | 集群信息 | 配置示例 |
FE配置 | 机型配置 | 通用型ecs.g7.4xlarge 16 Core 64 GB 系统盘:ESSD PL1 云盘 100 GB * 1块 数据盘:ESSD PL1 云盘 100 GB * 1块 |
节点数量 | 3台 | |
BE配置 | 机型配置 | 通用型ecs.g7.4xlarge 16 Core 64 GB 系统盘:ESSD PL1 云盘 100 GB * 1块 数据盘:ESSD PL1 云盘 1000 GB * 4块 |
节点数量 | 3台 | |
StarRocks版本号 | - | 例如:2.5.13 |
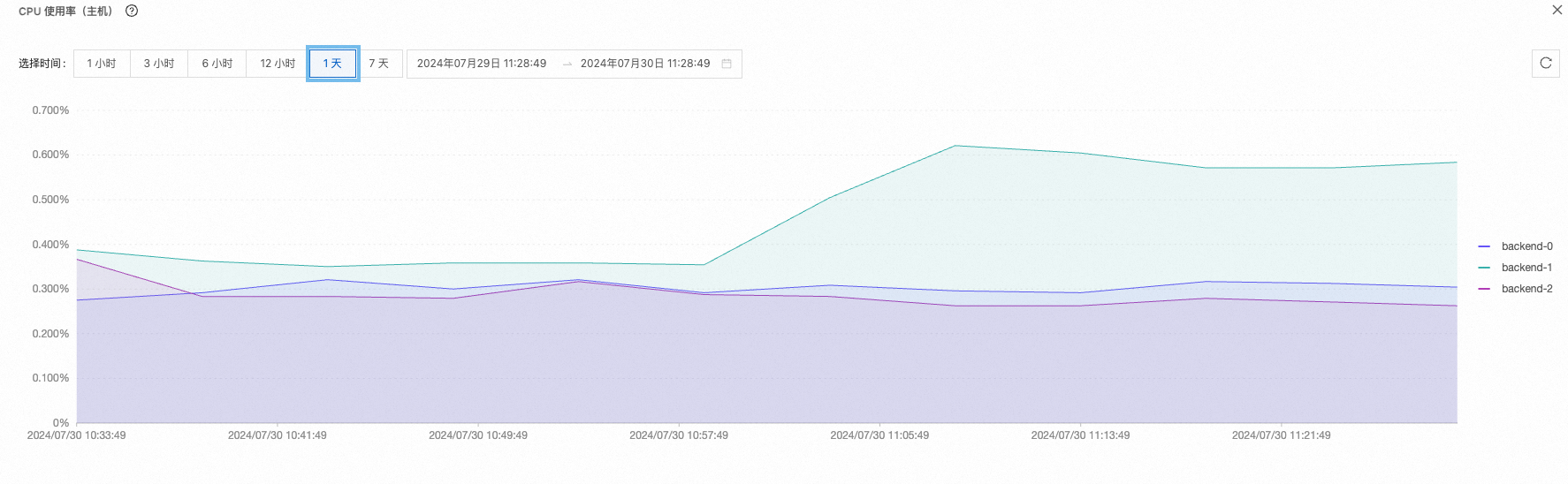
集群负载 | CPU负载 | 高峰:82.9% 低峰:50.3%
|
MEM负载 | 高峰:82.9% 低峰:50.3%
| |
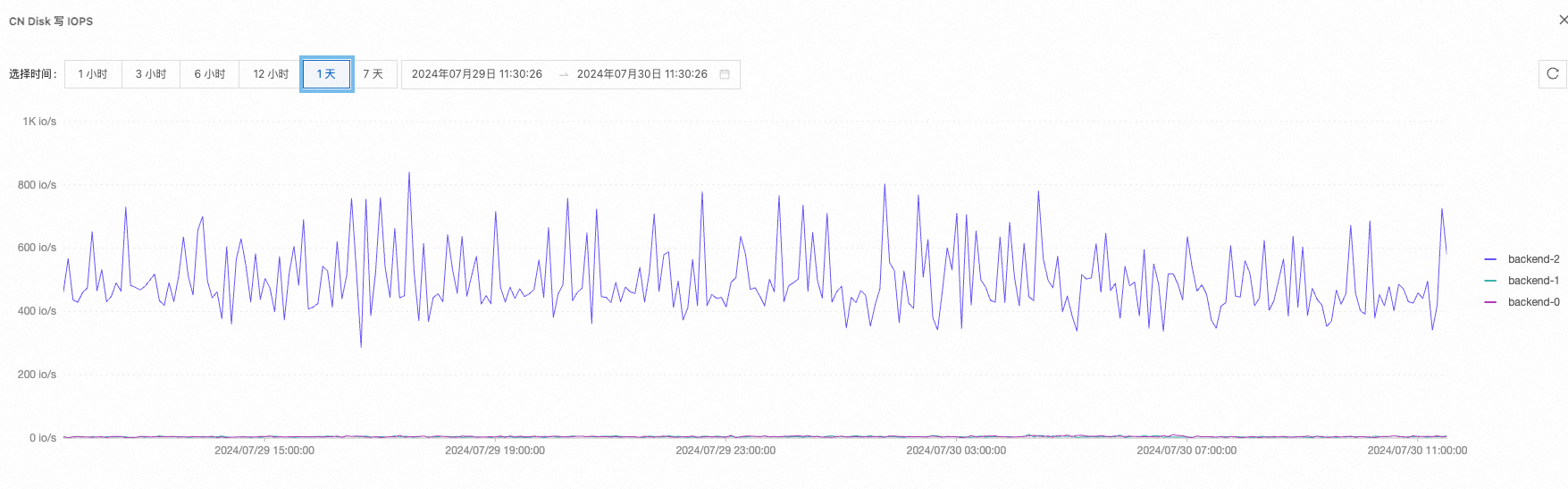
磁盘IOPS负载 | 高峰:10504 低峰:1003
| |
磁盘IO负载 | 高峰:514 MB/s 低峰:15 MB/s
|
确认业务使用情况
以下信息仅为配置示例,实际应用时需根据具体情况调整。
数据导入方式
数据导入方式
数据写入分类
每日数据增量
每日新行数
任务数
实时写入(Flink)
实时数据
10 GB
1 亿行
80
Kafka + Routine
实时数据
10 GB
1 亿行
20
离线导入(Spark Connector、DataX)
离线数据
10 GB
1 亿行
120
物化视图使用情况
物化视图
任务数
同步频率
同步物化视图
12个
无
异步物化视图
89个
大部分为每小时更新
Insert Overwrite
120个
大部分为每半小时更新
确认业务能够接受的停服时间
为了确保业务连续性,必须提前评估业务能够接受的停服时间。整个迁移的停服时间取决于具体方案,通常在30分钟至半天左右不等。因此,务必提前与业务方进行充分沟通,明确预期停服时间。
新建目标集群
建议目标集群与源集群的配置尽量保持一致,待业务文档运行后再根据负载情况灵活进行扩缩容。
根据您的业务需求,选择适当的实例类型创建Serverless StarRocks实例。您也可以通过钉钉群24010016636联系我们进行评估。参考文档如下:
数据迁移
1、安装迁移工具
该工具基于两个集群的元数据以及文件元数据对比,会定期将源集群的元数据以及数据增量同步到目标集群中。它作为迁移过程的一环,主要解决存量数据同步,元数据同步以及离线部分增量数据更新。
迁移工具的使用限制、安装、使用等信息,请参见StarRocks跨集群数据迁移工具。
迁移工具速率说明:
参考经验值:约1 TB/小时。
具体迁移速率受以下因素影响:同步的库表数量、表数据量、表分区数量以及桶的数量。对于单表来说,tablet数量越多,迁移速率会越慢。
远距离跨地域或跨VPC的迁移速率主要受网络稳定性影响。迁移过程中需要在两个集群之间建立大量连接,若网络不稳定或速率较慢,迁移速率也会受到显著影响。
迁移工具测试:在完成安装并正确配置了源集群与目标集群的详细信息后,进行工具的功能验证,确保其能够顺畅运作。
2、表结构&存量数据同步
通过上述迁移工具可以实现表结构以及存量数据的同步。您可以参考迁移工具的速率,同时结合实际测试情况来合理评估同步时间。通过配置迁移工具的以下2个参数,可以合理控制期望同步的表和数据的范围。
如果您需要迁移集群中所有数据库和表,则无须配置以下参数。
参数 | 说明 |
include_data_list | 需要迁移的数据库和表,多个对象时使用逗号( |
exclude_data_list | 不需要迁移的数据库和表,多个对象时使用逗号( |
3、实时任务迁移
如果您正在执行Flink或Kafka的实时写入任务,建议进行双写配置,以便同时将数据写入目标集群和源集群,从而确保数据一致性。
停止迁移工具:首先,停止当前的迁移工具,并调整配置,以排除对正在实时更新的表数据的同步。可通过
exclude_data_list参数进行控制。Flink作业:在Flink作业的平台上,复制现有任务,并修改数据源配置,指向目标集群。
Stream Load作业:在目标集群中手动创建相应的Stream Load作业,以实现对Kafka数据的双写同步。
在业务数据导入时,通常会有明确的offset或时间戳标识。例如,若同步任务于13:00启动并于13:30结束,目标集群表中至少应包含13:00之前的数据。同步任务结束后,可以将双写的Flink或Kafka任务设置到13:00之前的offset,以便完成迁移窗口期的数据追平工作。
4、离线任务迁移
离线任务启动:去掉实时更新的相关表后,继续启动离线任务,保持对离线更新数据的持续同步。
离线任务复制:复制离线任务实现对目标集群的更新,但在割接阶段之前暂时不启动相关任务。
确保提交离线任务的机器与目标集群之间的网络连接稳定,避免因网络问题导致任务失败。
选择1~2个任务进行验证,以确认离线任务流程的准确性和顺畅性。
5、(可选)物化视图迁移
请参考以下社区命令,以获取相关的物化视图或普通视图的定义。然后,在目标集群中逐个创建相应的视图。
6、(可选)外表迁移
3.x及之后版本,建议使用Catalog对StarRocks的外表进行统一管理。更多Catalog信息,请参见Catalog概述。
如果需要获取源表的DDL,可以通过SHOW CREATE TABLE命令,但不推荐在新集群中采用这种方式进行外表管理,建议优先使用Catalog。
根据您的具体需求,选择合适的方法在目标集群中创建外表,并测试外表功能是否正常。
7、(可选)UDF迁移
请参考SHOW FUNCTIONS命令,获取相关FUNCTION内容,并在目标集群中逐个创建相应的UDF。
在EMR Serverless StarRocks中,您的JAR等文件应存储在阿里云OSS中,使用以oss:为前缀的文件路径进行替换。
数据校验
1、数据一致性校验
数据一致性校验主要目的是验证同步数据的准确性,通过对源表与目标集群进行比较。可以从以下几个维度进行检查:
库或表数量对比
表记录数对比
每行记录的汇总或去重计数对比
如果源表与目标表存在轻微差异,可能是由于同步工具存在延迟导致的。建议结合业务场景,添加合适的时间戳,以进行更精准的校验。
2、下游业务校验
下游业务校验主要从业务角度出发,对结果进行验证,以确保源表、物化视图及其他预处理数据的正确性。具体校验方式如下:
有下游测试系统:可切换数据源至目标集群,从业务角度对查询结果和报表数据进行验证。
无下游测试系统,可采取以下两种方法:
业务SQL复现:手动挑选关键业务SQL,执行查询并比对结果,以进行校验。
生产环境验证:利用业务系统进行验证,此过程需与业务方提前协商,验证完成后应尽快切换回源集群。
如果业务结果数据存在轻微差异,建议结合业务场景,添加合适的时间戳,以进行更精准的校验。
3、性能验证
性能验证的关键在于复现实际生产业务的各种压力,包括数据导入、业务查询以及物化视图的处理。同时,必须确保实时数据的双跑、离线任务的同步处理以及物化视图的正常运行,以模拟真实的生产环境。以下是需要验证的要点:
集群负载:确保CPU、内存、磁盘IO、IOPS及磁盘利用率等各项指标均在预期范围内。
业务查询:验证业务查询的响应时间,确保其在业务需求的合理范围内。
数据导入:检查数据导入的延迟情况,确保其在业务需求的合理范围内。
业务割接
1、确认停服时间
由于业务割接将导致短暂停服,我们需要提前评估停服时间,并与业务方确认。建议在业务低峰期进行停服,以最小化对业务的影响。
通常情况下,割接的中断时间主要集中在第五步(即业务系统切换至目标集群)。此步骤预计耗时较短,预计30分钟至1小时。具体时间会根据项目情况进行实际评估。
2、终止源集群的离线数据同步
为确保割接时目标集群能够追平源集群的数据,请在割接前停止离线同步任务。这意味着需要选择适当的更新间隔期,并停止新数据的写入,确保源集群不再增加新的离线数据。
3、迁移工具持续同步,直至追平源集群
迁移工具将保持实时同步状态,直至与源集群数据完全一致。
观察时间至少10分钟,若此期间无新数据同步,则算追平源集群。
请确认所有离线写入任务已终止,避免迁移工具因持续更新而无法追平。
4、离线同步任务写入目标集群
在之前的迁移步骤中,已配置好离线任务写入目标集群。本步骤仅需启动这些任务,并观察其运行情况,重点校验:
同步任务是否正常运行。
目标集群的数据是否正常更新。
请确保同步任务的开始周期与原停止周期能够无缝对接。例如,如果上次停止更新的时间为2024年02月01日 00:00,则新任务应从该时间点的下一个周期启动。
5、业务系统切换为目标集群
将下游使用StarRocks的业务系统数据源配置切换为目标集群的配置,并验证业务系统的查询功能,确保查询耗时符合预期。
若业务系统需要进行大量配置修改,建议提前准备修改脚本,以缩短配置修改时间。
6、割接验证
割接后,对业务系统进行验证,主要从下游进行检验,验证项包括:
业务系统查询结果是否正确。
业务系统查询耗时是否符合预期。
如验证中发现问题,请参考回滚方案。
7、终止实时双跑任务
验证通过后,可以停止源集群的实时写入任务,正式完成割接。
回滚方案
如果割接后验证存在问题,请首先联系阿里云EMR团队协同解决相关问题。如果问题无法解决,再考虑回滚方案。回滚流程如下:
保持实时任务双跑,避免执行数据校验阶段的第7步操作(即终止实时双跑任务)。
将业务系统切换回源集群地址,验证业务系统是否正常运行。
从上次停止的周期开始,恢复离线任务对源集群的写入。
停止向目标集群写入离线数据。